One-Inclusion Graphs and the Optimal Sample Complexity of PAC Learning: Part 1
We’re back again with another post! In case you missed the first two in the series, on calibration and multi-class classification, please check them out.
Today, we have the first in a two-parter by Ishaq Aden-Ali, Yeshwanth Cherapanamjeri, Abhishek Shetty, and Nikita Zhivotovskiy, again on sample-efficient methods for PAC learning. In the first post, they revisit and discuss a refutation of the strong version of Warmuth’s one-inclusion graph conjecture.
Introduction
One of the key contributions of computer science is the formalization of the concept of learning. These definitions try to get at the heart of the question of what patterns can be recognized from examples. In this (and the next) blog post, we will discuss a probabilistic formalization of this question through the Probably Approximately Correct (PAC) model of learning, and we will try to understand how many examples are needed to learn a pattern with high probability over the data generating process, i.e. the sample complexity. Towards this goal of characterizing the optimal sample complexity, we will see connections between the PAC model and a model of learning known as transductive learning. Further, we will characterize learning in the transductive setting using an elegant combinatorial argument.
Finally, we will connect high probability PAC bounds to transductive learning using a general connection with online learning using a simple argument connecting beyond worst-case analysis of sequential decision-making can lead to sharp bounds in an a priori offline learning setting.
Probably Approximately Correct (PAC) Learning
The basic mathematical setup for learning involves a set 


![\left[ 0,1 \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+0%2C1+%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002)
The key modeling assumption is the presumption of the existence of a distribution 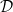
Since one cannot expect to learn arbitrary labelling functions, simplicity of the labelling function is usually encoded by assuming that the labelling function 
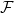
The learner, thus, has access to a training set 
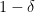


![\mathcal{R}(h) = \Pr_{X \sim \mathcal{D}}[h(X) \neq f^{\star}(X)] \leq \epsilon.](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BR%7D%28h%29+%3D+%5CPr_%7BX+%5Csim+%5Cmathcal%7BD%7D%7D%5Bh%28X%29+%5Cneq+f%5E%7B%5Cstar%7D%28X%29%5D+%5Cleq+%5Cepsilon.&bg=ffffff&fg=000&s=0&c=20201002)
We will refer to 

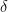

Empirical Risk Minimization
In the above model, given that there is a consistent hypothesis respecting the labels, a natural algorithm would be to find a function consistent with the labels seen so far. That is, output ![\tilde{f} \in \left\{ f \in \mathcal{F}: f(x_i) = y_i \; \forall i \in [n] \right\}](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bf%7D+%5Cin+%5Cleft%5C%7B+f+%5Cin+%5Cmathcal%7BF%7D%3A+f%28x_i%29+%3D+y_i+%5C%3B+%5Cforall+i+%5Cin+%5Bn%5D+%5Cright%5C%7D&bg=ffffff&fg=000&s=0&c=20201002)
The idea is to argue that if it is likely that a candidate function 
But, getting back to the ERM algorithm, we need a formal notion of complexity of the hypothesis class
Theorem 1 [VC Theorem, See e.g. [SB14]] Let 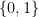



Let 



![\Pr_{X \sim D } \left[ f(X) \neq f^{\star}(X) \right] \leq \epsilon.](https://s0.wp.com/latex.php?latex=%5CPr_%7BX+%5Csim+D+%7D+%5Cleft%5B+f%28X%29+%5Cneq+f%5E%7B%5Cstar%7D%28X%29+%5Cright%5D+%5Cleq+%5Cepsilon.&bg=ffffff&fg=000&s=0&c=20201002)
Optimal Sample Complexity of PAC Learning
A natural question is to ask whether the sample complexity of the ERM algorithm is tight. Using simple arguments, one can show lower bounds on the sample complexity of any learning algorithm in terms of the parameters
Theorem 2 [Sample Complexity Lower Bound, See e.g. [SB14]] Let

Note that the upper and lower bounds differ by a factor of 
Theorem 3 [Optimal Sample Complexity of PAC Learning] Let

Let 
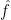
![\Pr_{x \sim D } \left[ \hat{f}(x) \neq f^{\star}(x) \right] \leq \epsilon.](https://s0.wp.com/latex.php?latex=%5CPr_%7Bx+%5Csim+D+%7D+%5Cleft%5B+%5Chat%7Bf%7D%28x%29+%5Cneq+f%5E%7B%5Cstar%7D%28x%29+%5Cright%5D+%5Cleq+%5Cepsilon.+&bg=ffffff&fg=000&s=0&c=20201002)
A key feature of the techniques we will see in this post is that they allow us to generalize from binary classification to more general settings, leading to a unified perspective on optimal PAC learning algorithms.
Transductive Learning and the One-Inclusion Graph Algorithm
In order to motivate Theorem 3, we will take a detour and discuss a learning setting known as transductive learning. We will view transductive learning as a game where a player is competing against an adversary. As before we will will fix a function class
- The adversary picks a set of examples
, a labelling function
, and produces the labelled set of examples
- A uniformly random permutation/shuffle is applied to these labelled examples to produce the random sequence
. Note that the examples are exchangeable.
- The player receives the first
as a training set as well as the last unlabelled example
as a test point”.
- The player now needs to produce a prediction
for the unknown label
of the test point using whatever information they can glean from the training set

![\Pr\left[\hat{Y}_{n+1} \neq f^\star(X_{n+1})\right].](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B%5Chat%7BY%7D_%7Bn%2B1%7D+%5Cneq+f%5E%5Cstar%28X_%7Bn%2B1%7D%29%5Cright%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Here, the probability is taken with respect to the randomness of the uniform permutation (and potentially any randomness of the learning algorithm). While this might seem quite strange at first glance, this setting focuses on the on exchangeability of the sample instead of independence as in the PAC model.
Furthermore, as we will see shortly, there is a natural combinatorial interpretation of this problem that leads to an elegant solution! To build some intuition, let’s consider a simple toy example.
As before, we will focus on the case of binary classification 

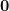







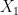








We can now rephrase our strategy for the toy example we considered above: once we compute the projection, we find all the patterns in 
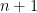


Lets take a step back and rephrase what we have learned from the above (we’ll see why this rephrasing is a good idea very soon). Given the examples 
- Each string
is a vertex, i.e.
.
- We connect an edge between two vertices
if and only if they disagree on exactly 1 bit (Hamming distance 1).
This graph is called the one-inclusion graph (OIG). Notice that for any fixed set of points 
We already noticed that if there is only a single vertex 



How should the player orient the graph so as to minimize their error? Since the error is measured with respect to a uniformly random permutation, and since the player’s strategy does not depend on the order of the dataset, its not too hard to see that the error they suffer is
![\Pr\left[\hat{Y}_{n+1} \neq f^\star(X_{n+1})\right] = \frac{1}{n+1} \sum_{i=1}^{n+1} \mathbf{1}\left\{\hat{y}_i \neq x_i\right\}.](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B%5Chat%7BY%7D_%7Bn%2B1%7D+%5Cneq+f%5E%5Cstar%28X_%7Bn%2B1%7D%29%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%2B1%7D+%5Cmathbf%7B1%7D%5Cleft%5C%7B%5Chat%7By%7D_i+%5Cneq+x_i%5Cright%5C%7D.&bg=ffffff&fg=000&s=0&c=20201002)
In words, this is the fraction of times that the player makes a mistake on a uniformly random choice of test point 
![\Pr\left[\hat{Y}_{n+1} \neq f^\star(X_{n+1})\right] = \frac{\mathrm{out-degree}(f^\star)}{n+1}.](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B%5Chat%7BY%7D_%7Bn%2B1%7D+%5Cneq+f%5E%5Cstar%28X_%7Bn%2B1%7D%29%5Cright%5D+%3D+%5Cfrac%7B%5Cmathrm%7Bout-degree%7D%28f%5E%5Cstar%29%7D%7Bn%2B1%7D.&bg=ffffff&fg=000&s=0&c=20201002)
The player thus wants to minimize the out-degree of
There is now one final question that remains: how small can the maximum out-degree of the one-inclusion graph be? It is a priori possible for some vertices in the graph to have degree 
Definition 1 [VC Dimension] Let 


Typically, the VC dimension is used in learning theory (for example in the proof of Theorem 1) to argue that the number of functions that a class can express on any dataset is small (through the celebrated Sauer-Shelah lemma). In the language of one-inclusion graphs, this amounts to arguing that the number of vertices of the one-inclusion graph is small. But as we noted above, the error in the transductive setting (and as we will see in the PAC setting as well) is bounded by out-degree of the best orientation of the one-inclusion graph. This turns out to be related to the edge density of the one-inclusion graph (this general fact can be argued using the Hall marriage theorem and was first presented by Alon and Tarsi [AT92]). Surprisingly, Haussler, Littlestone, and Warmuth [HLW94] proved a beautiful combinatorial result that states that the edge density (and thus the maximum out-degree) can always be made to be smaller than
Theorem 4 [Orientations of One-Inclusion Graphs] Let 

This result amounts to saying that one-inclusion graphs are very sparse. This can be seen as a version of the isoperimetry theorem on the Boolean hypercube and provides a complementary view on the VC dimension compared to the Sauer-Shelah lemma.
Though, in this post we are not focussed on the computational efficiency of our algorithms, we remark that the minimizing orientation can in fact be found efficiently (using flow algorithms) in the size of the one-inclusion graph but this graph can have size 
Going back to our game, we can combine the above and conclude that the player has a final error bound
![\Pr\left[\hat{Y}_{n+1} \neq f^\star(X_{n+1})\right] \leq \frac{d}{n+1}.](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B%5Chat%7BY%7D_%7Bn%2B1%7D+%5Cneq+f%5E%5Cstar%28X_%7Bn%2B1%7D%29%5Cright%5D+%5Cleq+%5Cfrac%7Bd%7D%7Bn%2B1%7D.&bg=ffffff&fg=000&s=0&c=20201002)
This result tells us that the VC dimension is a quantitative measure of complexity of the class that guarantees how well the player can perform. In fact, it is the quantitative measure of complexity for this game given the matching lower bounds of [LLS01] (this is the transductive analogue of Theorem 2).
We reiterate that a key aspect to note about the one-inclusion graph itself is that it does not depends on the order of the training examples 
The above argument was specialized to binary function classes, however it naturally extends to many other settings e.g. multiclass classification where instead of a graph, we have a hypergraph [RBR09, DS14]. In all these extensions, the one-inclusion strategy still works: we can minimize the maximum out-degree of the relevant one-inclusion (hyper)graph to achieve an upper bound on the error that scales with the maximum out-degree. Unfortunately, in more general settings it is not always clear whether the maximum out-degree can be made independent of the sample size
From Transductive learning to expected risk bounds
While the transductive model is interesting in its own right, our original goal was to understand how well we could do in the PAC model. The OIG algorithm only provides a single prediction for a test point 




![\pi: [n+1] \to [n+1]](https://s0.wp.com/latex.php?latex=%5Cpi%3A+%5Bn%2B1%5D+%5Cto+%5Bn%2B1%5D&bg=ffffff&fg=000&s=0&c=20201002)
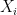

![\mathbb{E}_{S} \left[ \Pr_{X \sim P} \left[\widehat{f}_{\mathrm{OIG}}(X) \neq f^\star(X) \right]\right] = \mathbb{E}_{X_1, \dots, X_n} \left[\mathbb{E}_{X_{n+1}}\left[\mathbf{1}\left\{\widehat{f}_{\mathrm{OIG}}(X_{n+1}) \neq f^\star(X_{n+1}) \right\}\right]\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BS%7D+%5Cleft%5B+%5CPr_%7BX+%5Csim+P%7D+%5Cleft%5B%5Cwidehat%7Bf%7D_%7B%5Cmathrm%7BOIG%7D%7D%28X%29+%5Cneq+f%5E%5Cstar%28X%29+%5Cright%5D%5Cright%5D+%3D+%5Cmathbb%7BE%7D_%7BX_1%2C+%5Cdots%2C+X_n%7D+%5Cleft%5B%5Cmathbb%7BE%7D_%7BX_%7Bn%2B1%7D%7D%5Cleft%5B%5Cmathbf%7B1%7D%5Cleft%5C%7B%5Cwidehat%7Bf%7D_%7B%5Cmathrm%7BOIG%7D%7D%28X_%7Bn%2B1%7D%29+%5Cneq+f%5E%5Cstar%28X_%7Bn%2B1%7D%29+%5Cright%5C%7D%5Cright%5D%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![= \mathbb{E}_{\pi}\left[\mathbb{E}_{X_{\pi(1)}, \dots, X_{\pi(n)}} \left[\mathbb{E}_{X_{\pi(n+1)}}\left[\mathbf{1}\left\{\widehat{f}_{\mathrm{OIG}}(X_{n+1}) \neq f^\star(X_{n+1}) \right\}\right]\right]\right]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7B%5Cpi%7D%5Cleft%5B%5Cmathbb%7BE%7D_%7BX_%7B%5Cpi%281%29%7D%2C+%5Cdots%2C+X_%7B%5Cpi%28n%29%7D%7D+%5Cleft%5B%5Cmathbb%7BE%7D_%7BX_%7B%5Cpi%28n%2B1%29%7D%7D%5Cleft%5B%5Cmathbf%7B1%7D%5Cleft%5C%7B%5Cwidehat%7Bf%7D_%7B%5Cmathrm%7BOIG%7D%7D%28X_%7Bn%2B1%7D%29+%5Cneq+f%5E%5Cstar%28X_%7Bn%2B1%7D%29+%5Cright%5C%7D%5Cright%5D%5Cright%5D%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)

To get the final inequality above, we condition on the values of the 
Conjecture 1 [War04] The one-inclusion graph algorithm of [HLW94] always achieves the lower bound. That is, after receiving

examples, its error is at most 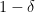
Some bad news
Unfortunately, Warmuth’s conjecture is false in the strictest sense as was shown in [AACS23b].
Theorem 5 [Informal] For any integer 
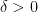



for some universal constant 
By valid, we mean the algorithm will always predict with a one-inclusion graph that has out-degree at most
Note that this hints at a fundamental difference between the PAC and the transductive setting. In the PAC setting, we need to worry about the behavior of the algorithm across different datasets while the transductive (and also the expectation version of the PAC setting) only requires us to worry about the behavior of the algorithm on (random permutations of) a single dataset. Intuitively, the lower bound is proven by coordinating” the mistakes of the one-inclusion graphs that the algorithm predicts with. Recall that the one-inclusion graph algorithm makes a mistake on a test point 

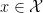

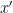
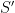
In the next episode of …
Unfortunately, we will have to end this blog post on this pessimistic note. But, stay tuned for the next blog post where we will see how we can combine techniques from online learning with the exchangeability that were key to the analysis of the OIG to design simple prediction strategies that achieve optimal high probability PAC bounds.
References
- [AACSZ23a] Ishaq Aden-Ali, Yeshwanth Cherapanamjeri, Abhishek Shetty, and Nikita Zhivotovskiy. Optimal PAC bounds without uniform convergence, In Foundations of Computer Science (FOCS), 2023.
- [AACSZ23b] Ishaq Aden-Ali, Yeshwanth Cherapanamjeri, Abhishek Shetty, and Nikita Zhivotovskiy. The one-inclusion graph algorithm is not always optimal. In Conference on Learning Theory (COLT), 2023.
- [AT92] Noga Alon and Michael Tarsi. Colorings and orientations of graphs. Combinatorica, 12(2):125–134, 1992.
- [DS14] Amit Daniely and Shai Shalev-Shwartz. Optimal learners for multiclass problems. In Conference on Learning Theory (COLT), 2014.
- [Han16] Steve Hanneke. The optimal sample complexity of PAC learning. The Journal of Machine Learning Research, 17(1):1319–1333, 2016.
- [HLW94] David Haussler, Nick Littlestone, and Manfred Warmuth. Predicting {0, 1}-functions on randomly drawn points. Information and Computation, 115(2):248–292, 1994.
- [Lit89] Nick Littlestone. From on-line to batch learning. In Proceedings of the Second Annual Workshop on Computational Learning Theory, 1989.
- [LLS01] Yi Li, Philip Long, and Aravind Srinivasan. The one-inclusion graph algorithm is near-optimal for the prediction model of learning. IEEE Transactions on Information Theory, 47(3):1257–1261, 2001.
- [RBR09] Benjamin Rubinstein, Peter Bartlett, and Hyam Rubinstein. Shifting: One-inclusion mistake bounds and sample compression. Journal of Computer and System Sciences, 75(1):37–59, 2009.
- [SB14] Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.
- [Sim15] Hans Simon. An almost optimal PAC algorithm. In Conference on Learning Theory (COLT), 2015.
- [War04] Manfred Warmuth. The optimal PAC algorithm. In International Conference on Computational Learning Theory (COLT), 2004.
Footnotes
- As stated the learner is not required to output a hypothesis in the class
- By reasonable, we mean the algorithm will never output a bit that is not possible, i.e. in the case that there is a single vertex to choose between it always picks the correct bit. ↩︎