Calibration for Decision Making: A Principled Approach to Trustworthy ML
The Learning Theory Alliance is starting a new initiative, with invited blog posts highlighting recent technical contributions to the field. The goal of these posts is to share noteworthy results with the community, in a more broadly accessible format than traditional research papers (i.e., self-contained and readable by a first-year graduate student). We’re kicking it off with the first in a series of posts about calibration, by Georgy Noarov and Aaron Roth.
TL;DR Calibration is a popular tool for uncertainty quantification. But what exactly is it good for? It turns out a lot! If predictions are calibrated, then for any downstream decision maker, it is a dominant strategy amongst all policies to treat the predictions as correct and act accordingly. This is a strong sense in which calibrated predictions are “trustworthy”. In all sorts of scenarios, this property implies desirable downstream guarantees. But calibration is hard to achieve in high-dimensional settings. Fortunately, in many concrete applications, full calibration is overkill. In a series of blog posts, we’ll describe a program, laid out more formally in [NRRX23], that aims to identify weaker conditions than calibration that suffice to give strong guarantees for particular downstream decision-making problems, and show how to achieve them efficiently.
Intro
Calibration and confidence What do we mean by calibrated prediction? Different research communities have come up with different definitions and interpretations of this notion throughout its over 40 years of existence [Daw82], but in a nutshell, the aim is to ensure that a predictive model is neither underconfident nor overconfident in its predictions.
The simplest illustration for this is in sequential binary prediction. Let’s say that every day, a weather prediction model observes some covariates and forecasts the likelihood of rain tomorrow (expressed as a number ![p_t \in [0, 1]](https://s0.wp.com/latex.php?latex=p_t+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)



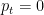
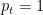


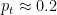
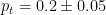
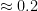
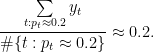
If the predictive model passes these sanity checks across all confidence levels 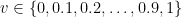
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Can this calibration condition always be satisfied in the challenging sequential prediction setting for any data generating process (i.e., no matter how the weather evolves across time)? It turns out that it can, and the first provable calibration methods appeared in the seminal line of work by Foster and Vohra [FV97, FV98, FV99]. While the result is now a classic and we may have become blasé about it, we shouldn’t forget how remarkable this is: as the authors recall, they had trouble getting their original paper published because the reviewers initially refused to believe the result could be true, and so thought that the proof (which in its first iterations was quite involved) must contain a bug.
Online vs. offline calibration Our informal discussion so far has focused on binary prediction and is situated in the online (adversarial sequential prediction) setting. That the definition is stated (and is attainable) online is great, as the online setting, where data arrives sequentially and may be generated by any, possibly time-evolving/adversarial process, is strictly more challenging than the standard distributional (also called batch/offline) setting. As such, statements about online calibration always directly imply batch counterparts via standard online-to-batch reductions; the main difference is that in the batch setting, they are stated using the language of (regular or conditional) expectations over an i.i.d. data distribution, whereas in the online world such expectations are interpreted as empirical averages over the sequence of predictions. For instance, re-stating our binary calibration definition in the distributional learning setting is easy: given any feature space 
![f: \mathcal{X} \to [0, 1]](https://s0.wp.com/latex.php?latex=f%3A+%5Cmathcal%7BX%7D+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb{E}}_{(x, y) \sim \mathcal{D}}[f(x) - y \, |\, f(x) \approx v] \approx 0,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%28x%2C+y%29+%5Csim+%5Cmathcal%7BD%7D%7D%5Bf%28x%29+-+y+%5C%2C+%7C%5C%2C+f%28x%29+%5Capprox+v%5D+%5Capprox+0%2C&bg=ffffff&fg=000&s=0&c=20201002)
where 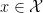
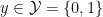

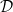
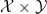
The results we’ll talk about in this blog post are for the more challenging online setting, but for notational simplicity we will sometimes use the batch setting notation. Just remember that in the online setting, the “distribution” is the empirical distribution over the sequence of outcomes, and an “expectation” is an average over this sequence.
Higher-dimensional calibration and the curse of dimensionality When the label space is binary, there is a single scalar parameter to estimate: the probability of the label taking value 1. So, ensuring appropriate confidence at all “confidence levels” is not such a daunting task, as one can form 

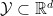




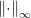
![\displaystyle \left\lVert \mathop{\mathbb{E}}_{(x, y) \sim \mathcal{D}}[ \, f(x) - y \, |\, f(x) \approx v] \right\rVert \approx 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5ClVert+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%28x%2C+y%29+%5Csim+%5Cmathcal%7BD%7D%7D%5B+%5C%2C+f%28x%29+-+y+%5C%2C+%7C%5C%2C+f%28x%29+%5Capprox+v%5D+%5Cright%5CrVert+%5Capprox+0.&bg=ffffff&fg=000&s=0&c=20201002)
An important use case for high-dimensional calibration is multiclass prediction. For instance, 




However, there is a curse-of-dimensionality issue, which makes this kind of calibration practically unattainable. Picking any bucket granularity 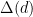

What is calibration good for anyway? Now (just as we are getting to the difficulties with calibration) is a good time to pause and ask why we want calibration in the first place. The perspective we will take is that predictions are valuable insofar as they can inform high-quality downstream actions by decision makers in a variety of environments. We’ll be more precise about this shortly, but informally, calibration has great decision-theoretic properties. Downstream decision makers (who might each have their own utility function that depends on the actions they could take and on the state of the world that a model is predicting) must choose a policy that maps the model’s predictions to actions. Calibration promises that, simultaneously for all downstream problems, the policy that treats the predictions of a calibrated model as correct and acts accordingly is uniformly best amongst all policies. The fact that “trusting” the decisions of a calibrated predictor is a dominant strategy in turn implies many kinds of downstream guarantees in particular problems. Here are just a few that we’ll talk about in this series:
- Decision making under high-dimensional uncertainty with strong regret guarantees;
- Conditional coverage guarantees for set-valued prediction;
- Ensembling many predictors to optimize multiple loss functions at once.
But if we have particular applications like these in mind, calibration might be overkill — after all, calibration is agnostic to the downstream task, and in a sense offers guarantees uniformly across all downstream tasks. The program that we describe in these blog posts seeks to:
- Focus on particular tasks that are downstream of prediction;
- Identify whether there are weaker conditions than full calibration that suffice to get (almost) the same desirable guarantees on decision-making quality as calibration would imply;
- Give fast algorithms obtaining these weaker guarantees that bypass the curse of dimensionality.
Event-Conditional Unbiased Prediction: A Framework for Decision-Focused Calibration

 Predictions Decisions pipeline.
Predictions Decisions pipeline.Now let us more concretely discuss a framework in which we can ask for guarantees that are weaker than full calibration, but can be targeted to specific downstream decision tasks. A similar decision-theoretic focus for calibration was advocated by [ZKSME21] in a batch setting. We’ll operate in an online learning setting, and focus on applications that make the most sense in this setting. A learner (us) competes against an adversary (the data generation process) in discrete rounds 
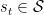
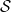
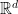
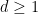
- The learner observes feature vector
, and makes (randomized) prediction
;
- The realized predicted state is sampled from the learner’s distribution:
;
- The adversary reveals the true state
What is the objective of this learning process? Ultimately, we want to produce predictions that are useful to downstream decision makers, but as an intermediate goal, we’ll study the goal of achieving event-unbiasedness. Similar definitions have been studied in the literature in various contexts (e.g. when 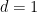
Definition (Event) A mapping2 ![E: \{1, \ldots, T_\mathrm{max}\} \times \mathcal{X} \times \mathcal{S} \to [0, 1]](https://s0.wp.com/latex.php?latex=E%3A+%5C%7B1%2C+%5Cldots%2C+T_%5Cmathrm%7Bmax%7D%5C%7D+%5Ctimes+%5Cmathcal%7BX%7D+%5Ctimes+%5Cmathcal%7BS%7D+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

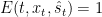
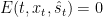

Each event basically describes a relevant subsequence in our data stream, conditional on which we want our predictions to be unbiased — i.e., correct on average. All of our applications in the program we describe will follow from appropriately instantiating these events for particular downstream decision-making problems, and producing predictions that are unbiased conditional on these events. This “event-conditional” terminology may sound a bit too abstract for now, but very soon we will see our first concrete example of how to usefully instantiate an event collection — specifically, in the case of online combinatorial optimization.
Definition (

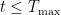
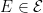

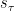
![\displaystyle \mathop{\mathbb{E}} \left[ \left\lVert \sum_{\tau=1}^t E(\tau, x_\tau, \hat{s}_\tau) \cdot (\hat{s}_\tau - s_\tau)\right\rVert_\infty \right] \leq O \left(\log (d \, |\mathcal{E}| \, T_\mathrm{max}) \cdot \sqrt{\mathop{\mathbb{E}} \left[ \sum_{\tau=1}^t (E(\tau, x_\tau, \hat{s}_\tau))^2 \right]} \right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb%7BE%7D%7D+%5Cleft%5B+%5Cleft%5ClVert+%5Csum_%7B%5Ctau%3D1%7D%5Et+E%28%5Ctau%2C+x_%5Ctau%2C+%5Chat%7Bs%7D_%5Ctau%29+%5Ccdot+%28%5Chat%7Bs%7D_%5Ctau+-+s_%5Ctau%29%5Cright%5CrVert_%5Cinfty+%5Cright%5D+%5Cleq+O+%5Cleft%28%5Clog+%28d+%5C%2C+%7C%5Cmathcal%7BE%7D%7C+%5C%2C+T_%5Cmathrm%7Bmax%7D%29+%5Ccdot+%5Csqrt%7B%5Cmathop%7B%5Cmathbb%7BE%7D%7D+%5Cleft%5B+%5Csum_%7B%5Ctau%3D1%7D%5Et+%28E%28%5Ctau%2C+x_%5Ctau%2C+%5Chat%7Bs%7D_%5Ctau%29%29%5E2+%5Cright%5D%7D+%5Cright%29.&bg=ffffff&fg=000&s=0&c=20201002)
Our definition of 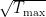
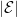
Driving the applications of this framework is the following general algorithmic result, which states that we can efficiently make predictions that attain this notion of event-conditional unbiasedness, in time polynomial in the number of events. We will provide the actual algorithm and its analysis in a follow-up blog post.
Theorem (Making 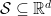
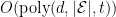
The upshot is that we can efficiently make high-dimensional predictions that are unbiased subject to any polynomial number of conditioning events. Full calibration is recovered by instantiating this bound with the exponential number of conditioning events corresponding to each
Straightforward Decision Making under Uncertainty
Consider a world inhabited by one or more strategic agents. Every day, these agents make decisions, which bring them varying amounts of utility depending on the state of the world on that day. The state of the world on that day only becomes known to the agents once they’ve committed to their decision for that day, and may be influenced in arbitrary ways by the past states of the world, the agents’ past decisions, and even by an adversary.
Example (Routing game) As a running example, let’s think about the problem of deciding, every morning, which route to take when driving from your home to your office. The actions you can take correspond to different paths in the road network that start at your home and end at your office — a potentially very large set. The state of the world corresponds to traffic conditions on each of the roads in the network, which affects your commute time — the thing you’d like to minimize. Traffic conditions could depend in unpredictable ways on all sorts of things: weather, sports events, construction, national holidays, etc. And there may be many people like you, interacting on the same road network, but with different origin-destination pairs and different tolerances for things like traffic vs. tolls vs. distance.

Modeling downstream decision makers (agents) Imagine one or more downstream agents, where each agent 
![u_i: \mathcal{A}_i \times \mathcal{S} \to [0, 1]](https://s0.wp.com/latex.php?latex=u_i%3A+%5Cmathcal%7BA%7D_i+%5Ctimes+%5Cmathcal%7BS%7D+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
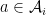
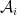
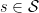
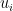
Each one of our utility-maximizing agents clearly would want to make optimal informed decisions: that is, if they knew the state of the world before they had to make their decision, they would choose the action that maximizes their own utility. The difficulty is that they have no access to the future, only to our predictions about it. Our guiding question is: What properties must a “good” prediction 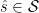

Example (Routing game; continued) Let us see how our running routing problem example fits into this formal setting. The problem is parameterized by a graph. Each agent 


Of course (as we’ll see in future blog posts), this abstract setting has many other applications. To start, let’s formally state and prove the very nice decision-theoretic property of full calibration that we’ve alluded to before: A (fully) calibrated prediction 
Theorem (Fully Calibrated Predictions Make Best-Responding Optimal) Suppose we make predictions ![\mathop{\mathbb{E}}[s | \hat{s}] = \hat{s}](https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5Bs+%7C+%5Chat%7Bs%7D%5D+%3D+%5Chat%7Bs%7D&bg=ffffff&fg=000&s=0&c=20201002)


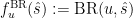

Proof
The claim follows right away from the definition of calibration and the linearity of the utility function in the state. For any prediction-to-decision policy 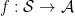
![\displaystyle \mathop{\mathbb{E}}_{s, \hat{s}}[u(f(\hat{s}), s)] = \mathop{\mathbb{E}}_{\hat{s}}[\mathop{\mathbb{E}}_s[u(f(\hat{s}), s)|\hat{s}]] = \mathop{\mathbb{E}}_{\hat{s}}[u(f(\hat{s}), \mathop{\mathbb{E}}_s[s|\hat{s}])] = \mathop{\mathbb{E}}_{\hat{s}}[u(f(\hat{s}), \hat{s})].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7Bs%2C+%5Chat%7Bs%7D%7D%5Bu%28f%28%5Chat%7Bs%7D%29%2C+s%29%5D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Chat%7Bs%7D%7D%5B%5Cmathop%7B%5Cmathbb%7BE%7D%7D_s%5Bu%28f%28%5Chat%7Bs%7D%29%2C+s%29%7C%5Chat%7Bs%7D%5D%5D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Chat%7Bs%7D%7D%5Bu%28f%28%5Chat%7Bs%7D%29%2C+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_s%5Bs%7C%5Chat%7Bs%7D%5D%29%5D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Chat%7Bs%7D%7D%5Bu%28f%28%5Chat%7Bs%7D%29%2C+%5Chat%7Bs%7D%29%5D.&bg=ffffff&fg=000&s=0&c=20201002)
What this says is that when the predictions are (fully) calibrated, the expected utility of any policy can be measured by simply assuming that our predictions 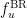
![\displaystyle \mathop{\mathbb{E}}_{s, \hat{s}}[u(f_u^\mathrm{BR}(\hat{s}), s)] = \mathop{\mathbb{E}}_{\hat{s}}[u(f_u^\mathrm{BR}(\hat{s}), \hat{s})] \geq \mathop{\mathbb{E}}_{\hat{s}}[u(f(\hat{s}), \hat{s})] = \mathop{\mathbb{E}}_{s, \hat{s}}[u(f(\hat{s}), s)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7Bs%2C+%5Chat%7Bs%7D%7D%5Bu%28f_u%5E%5Cmathrm%7BBR%7D%28%5Chat%7Bs%7D%29%2C+s%29%5D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Chat%7Bs%7D%7D%5Bu%28f_u%5E%5Cmathrm%7BBR%7D%28%5Chat%7Bs%7D%29%2C+%5Chat%7Bs%7D%29%5D+%5Cgeq+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Chat%7Bs%7D%7D%5Bu%28f%28%5Chat%7Bs%7D%29%2C+%5Chat%7Bs%7D%29%5D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7Bs%2C+%5Chat%7Bs%7D%7D%5Bu%28f%28%5Chat%7Bs%7D%29%2C+s%29%5D.+&bg=ffffff&fg=000&s=0&c=20201002)
The inequality follows because with respect to the predicted state 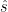
When encountering this claim, one would be forgiven for disbelief: how can calibration (which by itself doesn’t imply accurate prediction) be enough to make trusting the predictions an optimal policy? The catch is that the best-responding policy is only provably optimal among those policies that take only the predictions as input, and no other external context. If you know something more than the predictive algorithm, of course, you might want to act on it. Multicalibration mitigates this limitation; it asks for calibration to hold not just marginally, but conditionally in various ways on available external context [HJKRR18, KGZ19, GJNPR22, GHKRS23, HJZ23]. By multicalibrating forecasts with respect to the external information available to the downstream decision maker, we would recover the property that best-responding is an optimal policy for every downstream agent, even amongst policies that take external context into account.
A more efficient solution? As we’ve discussed, fully calibrating
Digging deeper, suppose we don’t care about all downstream decision makers, but instead know ahead of time a collection 

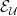

In fact, in the setting of online combinatorial optimization, which generalizes our routing example and in which agents can have very large action spaces 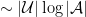
Application of Decision-Focused Calibration: No Subsequence Regret Guarantees for Online Combinatorial Optimization with Many Agents
Online combinatorial optimization Consider 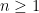
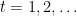

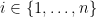
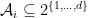
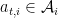
![r_t \in \mathcal{S} := [-1, 1]^{d}](https://s0.wp.com/latex.php?latex=r_t+%5Cin+%5Cmathcal%7BS%7D+%3A%3D+%5B-1%2C+1%5D%5E%7Bd%7D&bg=ffffff&fg=000&s=0&c=20201002)


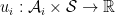

This generalizes the routing problem in a network with
What’s the objective? How do we define an agent’s total reward across the entire multi-round interaction? Across all rounds 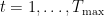
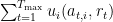
![\xi: \{1, \ldots, T_\mathrm{max}\} \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cxi%3A+%5C%7B1%2C+%5Cldots%2C+T_%5Cmathrm%7Bmax%7D%5C%7D+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
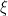
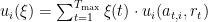
A standard online benchmark: No regret to the best action The simplest metric of success, which is ubiquitously used across various online learning settings, is for an agent to obtain small (external) regret, which means that her cumulative utility across all rounds is guaranteed to be in hindsight not much worse than it would have been had she chosen and stuck with repeatedly playing the best fixed action in hindsight across all rounds. We say that an agent has external regret at most 
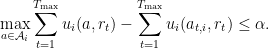
Since we are discussing agents whose action space
A stronger benchmark: Subsequence regret External regret is a relatively weak guarantee to an agent, because it is a promise that holds only on average over the sequence. Recall that traffic can be quite heterogeneous, and can depend on things that are observable to the agent, like weather, sports games, construction, etc. For example, it could be that following our forecasts guarantees an agent low external regret, but that she still knows that on rainy days (or on days when the predicted traffic seems to suggest that she should take I-76) she should actually do something else. So we’d like to be able to give agents stronger guarantees — that they should trust our forecasts even conditional on various other things they might know. We will model these guarantees as asking for no subsequence regret, which generalizes the notion of external regret to be measured over some subsequence ![\xi: \{1, \ldots, T_\mathrm{max}\} \times \mathcal{X} \times \mathcal{A}_i \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cxi%3A+%5C%7B1%2C+%5Cldots%2C+T_%5Cmathrm%7Bmax%7D%5C%7D+%5Ctimes+%5Cmathcal%7BX%7D+%5Ctimes+%5Cmathcal%7BA%7D_i+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
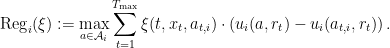
If there is only one subsequence the agent is interested in — or, for that matter, multiple non-overlapping subsequences — then as long as the subsequences are defined independently of the agent’s own actions, we could just run a separate copy of an off-the-shelf no-external-regret algorithm on every subsequence. This no longer makes sense for subsequences that depend on the agent’s action, since we would have now introduced a circularity. And naturally, the agent may simultaneously be interested in optimizing her regret over multiple overlapping subsequences: after all, rainy days, days when the Phillies are playing, and days when it seems to make sense to take I-76 are not mutually exclusive. So the question is: given a collection of subsequence functions 
An application of this program: No subsequence regret for agents who best-respond to predictions
In any online combinatorial optimization setting with a set of agents 
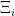

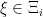
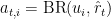
We’ll denote agent
Let 

Theorem (No-Subsequence Regret for Downstream Agents in Online Combinatorial Optimization [NRRX23])
Consider an online combinatorial optimization problem with 
![\displaystyle \mathop{\mathbb{E}}[\mathrm{Reg}_{t, i}(\xi)] = O \! \left( \!\! \sqrt{d \ln \left( \! d T_\mathrm{max} \! \sum_{i=1}^n \! |\Xi_i| \!\right) \! \cdot \! \mathop{\mathbb{E}}[\mathrm{len}_t(\xi)] } \! \right) \text{ for all } i, \xi \!\in\! \Xi_i, t \!\leq\! T_\mathrm{max}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5B%5Cmathrm%7BReg%7D_%7Bt%2C+i%7D%28%5Cxi%29%5D+%3D+O+%5C%21+%5Cleft%28+%5C%21%5C%21+%5Csqrt%7Bd+%5Cln+%5Cleft%28+%5C%21+d+T_%5Cmathrm%7Bmax%7D+%5C%21+%5Csum_%7Bi%3D1%7D%5En+%5C%21+%7C%5CXi_i%7C+%5C%21%5Cright%29+%5C%21+%5Ccdot+%5C%21+%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5B%5Cmathrm%7Blen%7D_t%28%5Cxi%29%5D+%7D+%5C%21+%5Cright%29+%5Ctext%7B+for+all+%7D+i%2C+%5Cxi+%5C%21%5Cin%5C%21+%5CXi_i%2C+t+%5C%21%5Cleq%5C%21+T_%5Cmathrm%7Bmax%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Moreover, the algorithm is computationally efficient (poly-time in 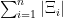
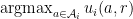
![r \in [-1, 1]^d](https://s0.wp.com/latex.php?latex=r+%5Cin+%5B-1%2C+1%5D%5Ed&bg=ffffff&fg=000&s=0&c=20201002)
Proof
The event collection 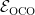
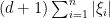

- An event
that is active whenever the corresponding subsequence is active, defined for all
;
- And, for every base element
that is active whenever the corresponding subsequence is active and when agent
, defined for all
(where
is the indicator of whether or not agent
What does this event collection accomplish? Informally, it will guarantee that on every relevant subsequence for any agent 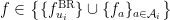

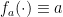
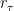

To be more formal, let us fix 

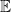
Helper Lemma 1: The unbiasedness of 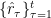

Proof of Helper Lemma 1: Recalling that
![\displaystyle \sum_{\tau=1}^{t} \!\! \xi(\!\tau\!, x_\tau\!, a_{\tau, i}\!) \!\cdot\! u_i(a_{\tau, i}, r_\tau\!) \!=\!\! \sum_{\tau=1}^{t} \! \xi(\!\tau\!, x_\tau\!, a_{\tau, i}\!) \!\!\! \sum_{e \in a_{\tau, i}} \!\!\! r_{\tau, e} \!=\!\! \sum_{e=1}^d \! \sum_{\tau=1}^{t} \! \xi(\!\tau\!, x_\tau\!, a_{\tau, i}\!) \!\cdot\! 1\![e \!\in\! a_{\tau, i}] \!\cdot\! r_{\tau, e}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7B%5Ctau%3D1%7D%5E%7Bt%7D+%5C%21%5C%21+%5Cxi%28%5C%21%5Ctau%5C%21%2C+x_%5Ctau%5C%21%2C+a_%7B%5Ctau%2C+i%7D%5C%21%29+%5C%21%5Ccdot%5C%21+u_i%28a_%7B%5Ctau%2C+i%7D%2C+r_%5Ctau%5C%21%29+%5C%21%3D%5C%21%5C%21+%5Csum_%7B%5Ctau%3D1%7D%5E%7Bt%7D+%5C%21+%5Cxi%28%5C%21%5Ctau%5C%21%2C+x_%5Ctau%5C%21%2C+a_%7B%5Ctau%2C+i%7D%5C%21%29+%5C%21%5C%21%5C%21+%5Csum_%7Be+%5Cin+a_%7B%5Ctau%2C+i%7D%7D+%5C%21%5C%21%5C%21+r_%7B%5Ctau%2C+e%7D+%5C%21%3D%5C%21%5C%21+%5Csum_%7Be%3D1%7D%5Ed+%5C%21+%5Csum_%7B%5Ctau%3D1%7D%5E%7Bt%7D+%5C%21+%5Cxi%28%5C%21%5Ctau%5C%21%2C+x_%5Ctau%5C%21%2C+a_%7B%5Ctau%2C+i%7D%5C%21%29+%5C%21%5Ccdot%5C%21+1%5C%21%5Be+%5C%21%5Cin%5C%21+a_%7B%5Ctau%2C+i%7D%5D+%5C%21%5Ccdot%5C%21+r_%7B%5Ctau%2C+e%7D&bg=ffffff&fg=000&s=0&c=20201002)
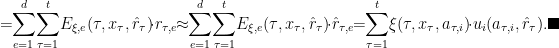
Helper Lemma 2: For every
Proof of Helper Lemma 2: Note the following (where the

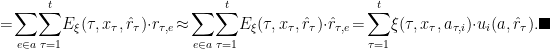
Now, by combining the guarantees that we just obtained for the total utilities of the best-response and the constant-action policies, we can see that for any benchmark action

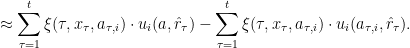
The right-hand side is 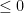
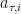

But now, the definition of subsequence regret gives us the desired result (for all 

Note that this proof has exactly the same structure as our earlier proof that the best-response policy is optimal amongst all prediction-to-action policies for all utility functions if the forecasts are fully calibrated. The difference is that here, with a restricted class of benchmark policies (the constant-action policies, for every subsequence) and a restricted class of utility functions (the “combinatorial” utilities
How does this compare to previous approaches? The algorithm of [BM07] can be used by a single agent to obtain no subsequence regret guarantees, but in time that depends polynomially on the number of actions — which in this case is exponential in the dimension. By working in prediction space rather than action space, we are able to get two big wins. First, we can produce a single set of predictions that is simultaneously useful to many downstream agents. Second, we get exponential computational savings by taking advantage of the low-dimensional structure of utility functions in these settings. We could of course have obtained a qualitatively similar (though quantitatively much worse) guarantee from calibration; but by examining what we actually needed to get these guarantees, we found that in fact unbiasedness subject to a polynomial collection of events sufficed. This will turn out to be a common theme in many problems.
Outro
In this blog post, we have:
- Discussed natural notions of calibration for predictive models;
- Showed how acting as if a calibrated model’s predictions are correct is optimal amongst all prediction-to-decision policies, simultaneously for all downstream agents, no matter what their utility functions might be;
- Hinted at the difficulty of (fully) calibrating high-dimensional predictions, and proposed a more flexible, decision-oriented notion of calibration that is much more efficient than full calibration in many natural decision pipelines;
- Demonstrated an example of the power of decision-focused calibration in adversarial / strategic settings, by showing that it yields strong, flexible, and coordinated no-regret guarantees for one or more agents playing in an online combinatorial optimization game (e.g., a routing game) — similar to what full calibration would imply, but at only a tiny fraction of its computational and statistical cost.
In the next post, we will continue to explore applications of this decision-focused calibration methodology, applying it to solve two more challenging online problems:
- Conformal prediction-style uncertainty quantification in online multiclass prediction; but without the need to choose a “conformity score”, and with stronger conditional guarantees;
- Online model ensembles that simultaneously optimize many loss functions at once.
This will further reinforce our broader conceptual point:
Calibration, and uncertainty quantification more generally, should be done with an eye towards — and in the service of — concrete downstream applications of our model’s predictions.
Footnotes
- There exist notions of calibration that avoid explicit bucketing [KF08, FH18, GKSZ22, BGHN23], but they will not be in our focus in this blog post. ↩︎
- In what follows, we omit any arguments to
that are implied or unused (like
References
- [BGHN23] Jaroslaw Blasiok, Parikshit Gopalan, Lunjia Hu, and Preetum Nakkiran. A unifying theory of distance from calibration, 2023
- [BM07] Avrim Blum and Yishay Mansour. From external to internal regret, 2007
- [Daw82] A Philip Dawid. The well-calibrated Bayesian, 1982
- [FH18] Dean P Foster and Sergiu Hart. Smooth calibration, leaky forecasts, finite recall, and Nash dynamics, 2018
- [FV97] Dean P Foster and Rakesh V Vohra. Calibrated learning and correlated equilibrium, 1997
- [FV98] Dean P Foster and Rakesh V Vohra. Asymptotic calibration, 1998
- [FV99] Dean P Foster and Rakesh V Vohra. Regret in the on-line decision problem, 1999
- [GHKRS23] Ira Globus-Harris, Declan Harrison, Michael Kearns, Aaron Roth, and Jessica Sorrell. Multicalibration as boosting for regression, 2023
- [GJNPR22] Varun Gupta, Christopher Jung, Georgy Noarov, Mallesh M Pai, and Aaron Roth. Online multivalid learning: Means, moments, and prediction intervals, 2022
- [GKSZ22] Parikshit Gopalan, Michael P Kim, Mihir A Singhal, and Shengjia Zhao. Low-degree multicalibration, 2022
- [HJKRR18] Ursula Hebert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. Multicalibration: Calibration for the (computationally-identifiable) masses, 2018
- [HJZ23] Nika Haghtalab, Michael I Jordan, and Eric Zhao. A unifying perspective on multicalibration: Game dynamics for multi-objective learning, 2023
- [KF08] Sham M Kakade and Dean P Foster. Deterministic calibration and Nash equilibrium, 2008
- [KGZ19] Michael P Kim, Amirata Ghorbani, and James Zou. Multiaccuracy: Black-box post-processing for fairness in classification, 2019
- [KV05] Adam Kalai and Santosh Vempala. Efficient algorithms for online decision problems, 2005
- [NRRX23] Georgy Noarov, Ramya Ramalingam, Aaron Roth, and Stephan Xie. High-dimensional prediction for sequential decision making, 2023
- [TW03] Eiji Takimoto and Manfred K Warmuth. Path kernels and multiplicative updates, 2003
- [ZKSME21] Shengjia Zhao, Michael Kim, Roshni Sahoo, Tengyu Ma, and Stefano Ermon. Calibrating predictions to decisions: A novel approach to multi-class calibration, 2021
Some of the math expressions are hard to read on mobile, starting just after “The learner observes feature vector”