Watermarking language models
Watermarking of language models is a challenging and important problem, where theory and algorithms play an essential role. Rohith Kuditipudi guides us through some of the latest advancements in the area.
The provenance problem
Language models today are able to mass produce fluent, human-like text. This reality poses unprecedented challenges for establishing text provenance while also placing renewed emphasis on its importance. Reliable tools for distinguishing human versus machine-generated text—and attributing text to particular language models—can empower individuals like online platform moderators and teachers to enact and enforce policies on language model usage; moreover, these tools can better enable model providers themselves (e.g., OpenAI) to track the (mis)use of their models, e.g., to scrub synthetic text from the training data of future language models.
A natural approach to developing such a tool is to collect many examples of text generated by humans versus language models and learn a classifier. Unfortunately however, the difficulty of this classification problem scales directly with the quality of the language models. In particular, model providers explicitly optimize language models to maximize the log-likelihood of human-generated text; the better these providers are able to optimize this objective, the harder it becomes to tell apart machine-generated text. Moreover, machine-learned classifiers are prone to issues such as distribution shift and miscalibration, issues which can have serious consequences in the wild (e.g., falsely accusing a student of plagiarism).
In this blog post, we will cover our work [KTHL’23] on an alternative approach to text provenance: watermarking. To achieve provenance, a watermark is a signal embedded within some generated content—in our case, text from a language model—that encodes the source of the content. We consider a setting where an untrusted third party user queries a language model by sending prompts to a trusted provider: the model provider generates text from their language model with a watermark—which they compute using a (secret) key—so that they may later identify the source of the text if the user publishes it. Essentially, watermarking circumvents the difficulty of classifying human versus machine-generated text by introducing side-information: the idea is that even if the distribution of unwatermarked text is *identical* to watermarked text, the joint distributions of the texts and the watermark key will be easily distinguishable.
Statistical Watermarking
Problem setup
Let 




- The model provider generates a random watermark key
for
;
- The user sends a prompt
- The model provider generates text
by
;
- The user publishes text
, which may be either (i) (an edited version of) the generated text
or (ii) text independent of
- The provider determines if
is watermarked—i.e., if
with respect to the null hypothesis that Ye is independent of ξ (i.e., not watermarked).
We collectively refer to the tuple 
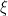

is equal to the original language model’s sampling distribution. Second, it should be reliable by enabling exact control of false positive (Type I) errors. Finally, it should be robust: the provider should be able to detect the watermark even if Ye is not an exact copy of watermarked text.
Designing a watermarking scheme
When we sample text from an autoregressive language model, under the hood the computer generates each token by mapping a random seed to a sample from the model’s output distribution.

The basic premise of statistical watermarking is to use a watermark key in place of a random seed and define a transformation from the key to tokens that enables downstream identification of watermarked token sequences.

In our scheme, we take ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


We use this correlation to define a test statistic for detecting watermarked text downstream. The test statistic compares the indices of tokens in a putative watermarked text (normalized by the vocabulary size) to subsequences of the watermark key. We would expect the value of the test statistic to be smaller for watermarked versus unwatermarked text (since the token indices of watermarked text are positively correlated with the subsequence of the watermark key which we used to generate the text). Because we do not know which subsequence of

We can obtain exact p-values from *any* such test statistic using a permutation test: we generate 






Already, this test is robust to a user swapping some fraction of tokens in a watermarked text with synonyms, since the remaining token identities will still exhibit correlation with the watermark key. However, it is not robust to inserting or deleting tokens (e.g., inserting a filler word) since these types of edits will cause misalignment between the entire text and the key. We address this issue in the paper by using techniques for robust sequence alignment to align a putative watermarked text to the watermark key sequence. Namely, we define a variation of Levenshtein “distance” between token sequences and watermark keys and use it in place of the 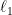
The main distinguishing feature of statistical watermarking in general is reliability: as we will see shortly, we can identify watermarked text from just a handful of tokens while provably controlling the likelihood of a false positive. What distinguishes our watermarking scheme in particular is that it is both distortion-free and robust. Other schemes [KGW+’23; AK’23; CGZ’23]—at least, all those prior and contemporaneous to ours—determine the next watermarked token based on a hash of the most recent tokens for some window size (illustrated below). The provider commits to a random hash function beforehand, which serves as the watermark key. Using a hash function as the watermark key introduces a direct trade-off between robustness and distortion: increasing the window size hurts robustness (since replacing any one of the tokens in the previous window will obfuscate the watermark in the current token), but small window sizes increase the likelihood of a hash collision, skewing the distribution of watermarked text away from the original language model. (We give some examples of this skewed behavior in our paper.)

Evaluating its effectiveness
In theory…
We can reliably detect watermarked text from just a few tokens. In particular, suppose we generate 



In other words, applying a basic concentration argument (i.e., a Hoeffding bound), we should expect to obtain p-values for watermarked text that are exponentially small in the length of the text. The factor of
One way to understand the effectiveness of watermarking is by analogy to a randomly generated error-correcting code. We generate m watermarked tokens x from a “codeword” of length
One caveat is that watermarking is only effective on language models with sufficient entropy. In the above analysis, we treated the per-token entropy of the language model as a hidden constant. As entropy tends to zero it becomes more difficult to detect the watermark. This trade-off is inevitable for any distortion-free watermark (not just ours). As an extreme example, if a user asks a language model to recite the alphabet, then the (correct) output will be the same regardless of whether we apply a watermark. To formalize this intuition, let 


This bound implies we cannot reliably tell apart watermarked versus non-watermarked text (i.e., 
…and in practice
We benchmark our watermarks by using the Llama 7B language model to generate completions of random C4 prompts (Figure 5). Throughout, we use “ITS” to refer to the inverse transform sampling watermark we have described above and “ITS-edit” to refer to the more robust version thereof using Levenshtein distance. We also tried using exponential minimum sampling (proposed by [AK’23]) as an alternative to inverse transform sampling—i.e., “EXP” and “EXP-edit”. We compare the effectiveness of our watermarks against the prior work of [KGW+’23]. That said, the comparison is not quite apples to apples since the watermarks of [KGW+’23] are not distortion-free; in particular, they bias the logits of the language model by a certain amount (larger 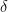

All watermarks are reliably detectable from less than 50 tokens, which in practice amounts to a few short sentences of text. The strongest watermarks (i.e., EXP and KGW-2.0) are all robust to randomly substituting large fractions of tokens. However, only EXP-edit is robust to randomly inserting and deleting tokens. In an attempt to simulate more realistic paraphrasing (e.g., a human editing watermarked text), we tried translating watermarked text to various languages (French and Russian) and back to English and found that the EXP-edit watermark is often still detectable. That said, in practice a user can easily evade detection by generating watermarked text in (eg) French and then translating back to English; even today, we are not aware of any distortion-free watermark that is robust to this kind of evasion attack.

Next steps
So far in this blog post, we’ve covered the basics of statistical watermarking and seen how effective these watermarks can be. That said, as we’ve already alluded to earlier, there are a number of open questions and challenges remaining.
The watermarks we have proposed are distortion-free and robust. However, detection is expensive; in particular, its runtime scales linearly in the length of the watermark key, which imposes a hard cap on the total number of distortion-free watermarked tokens we can generate. Thus, our watermarks exhibit a trade-off between detection runtime complexity and distortion. Revisiting the earlier analogy to error-correcting codes, the most naive strategy of decoding using a look-up table entails that the runtime of decoding scales linearly with the number of codewords. A recent and exciting line of work has developed families of pseudorandom error-correcting codes that are indistinguishable from random codes (like ours) yet admit efficient decoding algorithms [CG’24; GM’24; GG’24]. When applied to watermarking, in principle these codes enable schemes that are simultaneously distortion-free, and computationally efficient, and robust to a (sufficiently small) constant fraction of substitutions, insertions and deletions. In practice, the robustness of these schemes is not great; put differently, there remains much room for future work on improved constructions of pseudorandom codes!
Of course, stepping back one might argue that measuring robustness with respect to the fraction of tokens that are substituted, inserted, or deleted in watermarked text does not capture the kinds of evasion attacks to which we would like to be robust in the real world. For example, the attack we mentioned earlier of generating watermarked text in French and then translating to English (perhaps using a much smaller and/or cheaper model to do the translation step) would result in almost the entire translated token sequence being different from the original, despite being fairly cheap to implement. Other work has proposed recursively paraphrasing watermarked text (again, using a much cheaper model) to evade detection while maintaining the quality of the text. It remains a major open question to what extent robustness to these more general kinds of automated attacks is achievable.
Finally, the kinds of watermarks we have discussed in this blog post are all inapplicable to open-weight and open-source models, since they must be applied by the model provider at generation time. Even setting aside robustness, developing reliable and distortion-free (for some appropriate definition of distortion) watermarks for these kinds of models is an exciting and important direction for future work.
References
[KTHL’23] Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. (2023) Robust Distortion-free Watermarks for Language Models.
[KGW+’23] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. (2023) A Watermark for Large Language Models.
[AK’23] Scott Aaronson and Hendrik Kirchner. (2023) Watermarking GPT Outputs.
[CGZ’24] Miranda Christ, Sam Gunn, and Or Zamir. (2023) Undetectable Watermarks for Language Models.
[CG’24] Miranda Christ and Sam Gunn. (2024) Pseudorandom Error-Correcting Codes.
[GM’24] Noah Golowich and Ankur Moitra. (2024) Edit Distance Robust Watermarks for Language Models.
[GG’24] Surendra Ghentiyala and Venkatesan Guruswami. (2024) New Constructions of Pseudorandom Codes.