Incentivizing “Desirable” Effort in Strategic Classification
Today’s post, by Diptangshu Sen and Juba Ziani, is about strategic classification: the interesting setting where incentives and rational agents enter the learning process. Read on to learn more!
A gentle introduction to Strategic Classification
Machine learning systems are ubiquitous in many aspects of our lives. In recent years, they have been increasingly used to assist and sometimes even entirely replace human decision-making. AI tools have found large-scale use in many high-stakes settings that impact human lives long-term, like loan applications, university admissions, and criminal justice to name a few.
These systems may be complicated, but at their core, they usually function in the following way. First, a machine learning algorithm takes an agent’s features as input — for example, an individual’s financial history if they are going up for a mortgage. Then, the algorithm maps these features to an output in the form of either i) a score (e.g., credit scores in the United States) or ii) a decision (e.g., whether an individual is approved for a loan). In the second case, we talk about a positive classification outcome if the applicant gets the loan, and a negative classification outcome if they do not. Typically, much of these AI tools make the (implicit or explicit) assumption that the input data is independently and identically (i.i.d.) distributed. The i.i.d. assumption is central to guarantees like unbiasedness and generalization that these tools often claim to provide.
Unfortunately, real life is not this clean. Even absent human behavior, typical datasets do not satisfy the i.i.d. assumption: datasets are often inherently biased, incomplete, and unbalanced due to uneven data collection and sampling biases; data points may be correlated; labels and annotations (especially when done by humans) may be inconsistent; test and deployment data might be from a different distribution from the training data; datasets are not static and may evolve over time; etc. While the previous list is non-exhaustive, it aims to give the reader a sense of the variety and the complexity of reasons why typical assumptions in machine learning may fail.
The focus of this blog is, however, to tie this failure to human behavior. In particular, when faced with high-stakes decisions that can inform their lives or careers in the long term, humans tend to be strategic. By strategic, we mean that an individual may not face the classifier at face value and accept whatever decisions comes out of it. Instead, they may try to influence and steer the decision-making tool towards a positive scoring or classification outcome. In particular, individuals may try to modify their features in order to improve their outcomes — e.g., opening new credit card accounts to lower credit usage, which would improve their credit score (in fact, a quick internet search yields dozens of websites giving individuals financial advice on how to improve their credit score at minimal cost and effort). Change in features induces a distribution shift in the input data faced by the classifier, meaning it may be making decisions on data that significantly differs from its training data, leading to inaccuracies, loss of efficiency, and potential societal harms. The area of research that aims to understand how strategic human behavior affects classification outcomes was pioneered by Hardt et al. (2016) and coined Strategic Classification.
Beyond Traditional Strategic Classification
The current blog aims to study recent developments in strategic classification that aim to take it one step closer to reality, and focuses on our recent work Efthymiou et al. (2025). This mandates some context: what is the current state of strategic classification, and what are the current gaps with reality? We identify two main gaps below that our work aims to address.
Gaming vs Improvement. The initial view of Hardt et al. (2016) was that humans systematically try to game the system, i.e., humans try to “lie” about their features in order to trick the classifier into making wrong decisions (in their favor). This can, for example, be seen as a student cheating on a problem set or an individual artificially inflating their credit score by opening dummy credit card accounts. However, agents may modify their features in ways that are, in fact, valuable: a student may decide to invest more effort reviewing the material or engaging with a course to improve their grade; a loan applicant may start paying their bills consistently and on time to increase their credit score. In the space of strategic classification, it is important to distinguish what is gaming the classifier and what is investing in legitimate improvements to pass the classifier.
This distinction between gaming vs improvement has been studied in the literature (Miller et al. (2020), Shavit et al. (2020), Kleinberg and Raghavan (2020), Bechavod et al. (2021)). One aspect that all these works have in common is the way they model this important distinction: i.e., via a causal graph. Causality provides a natural framework to understand the causes behind changes in features. For example, a student may have improved their performance in class, but this may either be because they studied harder or because they cheated on homeworks. Causality allows us to present such potentially unobserved actions (cheating vs studying) as causal roots of the observed features (improved performance) faced by a classifier. Our recent work adopts such a causal framework.
Our work proposes a slightly different distinction than gaming vs improvement, instead focusing on desirable and undesirable effort. While these concepts are closely connected (gaming can often be seen as undesirable), the concepts do not exactly map one-to-one. Even some forms of improvement might be considered undesirable by a learner; for a concrete example, see our experimental case study which focuses on lowering the risk of cardiovascular disease (CVD)—there, we take a common view in the medical field that while both pharmaceutical and lifestyle interventions can both significantly lower one’s risk of CVD, lifestyle interventions, largely free of side effects, are preferred as a first line of prevention.
Incomplete Information. Recently, there has been some interest in studying the problem of strategic classification when agents have imperfect or incomplete information about the classifier (Ghalme et al. (2021), Bechavod et al. (2022), Cohen et al. (2024), Ebrahimi et al. (2024)). This is highly relevant in practice — in most real-life settings, the deployed classifier is unknown or only partially known to agents for a multitude of reasons. This may be because of privacy reasons that prevent model or training data transparency; high model complexity (think neural nets or large language models); or the model being proprietary. Think for example of credit scoring rules; it is generally understood which features are important (length of credit history; number of credit accounts; history of repayment of loans or credit; borrowing history; credit utilization; etc.), but it is not fully understood i) how each of these features are rated and ii) how they are put together into a single numerical score.
Another major source of uncertainty, that has not been studied in the context of strategic classification to the best of our knowledge, arises from agents not fully knowing the causal relationship between features. Going back to our running case study, an individual may know that reducing their alcohol consumption would lower their risk of CVD, but may not know the exact strength of this causal relationship. In fact, there is still a lot of debate on whether obesity is a cause of CVD or a symptom of related metabolic conditions, and what the specific causal path between obesity and CVD is. This can in turn impede their ability to understand how the effort they invest translates into a change in features, and to choose a reliable course of action to improve their outcomes. To the best of our knowledge, our paper Efthymiou et al. (2025) is the first to propose a framework that can model agents with uncertainty about both the deployed classifier and the underlying causal graph.
Our Work (Efthymiou et al. (2025))
Problem Setting
Model. Each agent in our model is represented by a feature vector 

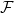
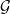
Now, the principal or learner deploys a linear classifier 






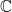 .
.The agent’s decision problem is the following: Given
- Since features are not independent, modifying one may directly or indirectly modify another feature. We measure the importance of a feature by its ability to affect other features. Intuitively, modifying an “important” feature appears to be more beneficial because it creates a cascading effect by simultaneously improving many features. We capture this phenomenon using a contribution matrix
. The contribution matrix is very useful because it helps to map any effort vector
to change
in feature vector
. We also show that
- The other aspect is that investing any effort incurs cost. Additionally, there may be cost-heterogeneity across features, i.e., it may cost more to invest unit effort into some features compared to others. For instance, in the earlier loan example, paying off existing debts in a timely manner requires consistent effort on the part of the agent over a long period, while opening new credit card accounts often only requires a few clicks. In our work, we primarily use weighted
-norm costs (
) for agents:

The agent’s goal is, therefore, to find the optimal effort vector 
Desirable vs Undesirable Effort Profiles. We have already motivated why all effort profiles are not the same — in the sense that some may be more desirable than others. The principal (entity who owns/deploys the classifier) naturally has incentives to design classifiers the induce desirable effort from agents. The principal, in our setting, gets to decide which types of efforts or which features they deem desirable; our framework makes no assumption about how the principal makes this decision, and takes the sets of desirable and undesirable features as an input.
We adopt one of the examples in (Kleinberg and Raghavan 2020) to illustrate this point. Consider a course where students are evaluated based on two metrics (in our context, features): their understanding of the course material and performance on tests/assignments. The professor’s goal is to incentivize students to invest more effort in the former (studying) rather than just the latter (rote-learning or cheating). There is a clear distinction between desirable and undesirable features from the professor’s (principal’s) perspective.
Formally, we model this as a partition of the set of features 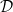

![\beta \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cin+%280%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)


where 

Main Results
Uncertainty or lack of information plays a key role in determining how agents best respond to the classifier. This, in turn, directly influences how the principal should design the classifier if the final goal is to induce desirable effort from agents. To the best of our knowledge, our work is the first to bring uncertainty to the study of incentivizing desirable effort in causal strategic classification problems. In particular, we try to answer two key questions under complete and incomplete information settings:
- How does a strategic agent choose their optimal effort profile?
- What are the properties of the design space of “desirable” classifiers ?
There are two main sources of uncertainty in our setting: the principal’s classifier and the feature causal graph. We model uncertainty as agents having Gaussian priors over the classifier weights and the edge weights of the causal graph (while graph topology is assumed common knowledge). This model captures a significant spectrum of uncertainty, including complete information, partially incomplete information (uncertainty lies in either the classifier or the causal graph but not both), and total incomplete information (with uncertainty over both the classifier and the causal graph).
Complete Information. In this case, every agent has complete information about the classifier 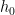

Recall that 
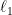
Theorem 1. For any 
when
; and
when
,
with
This is a strong result in the sense that it provides the principal with necessary and sufficient conditions to find desirable classifiers for a broad class of agent cost functions. At this point, it is important to highlight the differences of our results with those of (Kleinberg and Raghavan 2020). For their main result, they show that given any effort profile, it is possible to check whether there exists a classifier that can induce that profile. Further, if such a classifier exists, then there must also exist a linear classifier which induces the same profile. This result relies on agents having linear cost functions, as is the case in (Kleinberg and Raghavan 2020). Our paper Efthymiou et al. (2025) further demonstrates that the picture changes when agent cost functions come from a slightly more general class (for example, all
Despite the closed-form characterization of the design space of “good” classifiers as provided in Theorem 1, this space is, quite unfortunately, non-convex in the general case. This is grim because it essentially implies that searching for desirable classifiers while also optimizing for accuracy is likely to be difficult. We show heuristic ways to circumvent this issue in the full version of our paper Efthymiou et al. (2025).
Incomplete Information. The incomplete information setting comes with a fresh set of challenges. First of all, unlike the complete information setting, it is no longer guaranteed that an agent can always pass the classifier with sufficient effort. The agent’s goal is, therefore, to choose an effort profile which passes the classifier with high probability. The introduction of probabilistic constraints makes the agent’s optimization problem significantly more involved. And if agents cannot best respond reliably, the question of finding classifiers that can induce them to behave desirably is even harder. We will briefly touch upon our main results in this setting.
While the agent’s optimization problem is non-convex (and likely to be hard) under total incomplete information, we show that there are some settings with partial uncertainty where the problem is still convex and can be solved efficiently. In special cases, the optimal effort profile also has a nice structure: the agent is found to prioritize effort investment in features with high mean importance (as expected) and actively avoid investing effort into features for which she has a high degree of uncertainty (high variance in importance). This enables us to characterize conditions on the classifier which can induce desirable agent behavior under uniform uncertainty across features. Perhaps more interestingly, this observation also generalizes to much broader settings with incomplete information which we demonstrate with numerical experiments using data from a medical study looking at cardio-vascular disease risk in adults.
Case Study. Our experimental study focuses on a setting where the principal is trying to reduce a population’s risk of cardiovascular disease (CVD). To do so, we identify relevant features and build a causal graph based on the recent medical study by Hasani et al. (2024). We exclude immutable features such as age, gender and ethnicity, focusing instead on eight modifiable features: alcohol consumption, diet, physical activity, smoking, diabetes mellitus (DM), hyperlipidemia (HPL), hypertension (HPT), and obesity. Among these, we designate as desirable the features corresponding to lifestyle interventions—namely, alcohol, diet, physical activity, and smoking over those corresponding to medical conditions or interventions (DM, HPL, HPT, and obesity).

This is a carefully chosen example because it highlights how our framework can model scenarios beyond just gaming and improvement. Observe that in this example, neither lifestyle interventions nor medical interventions can be classified as “gaming” behavior. However, lifestyle interventions are clearly more desirable because medical interventions are often associated with long-term unfavorable side effects. In our experiments, we focus exclusively on the incomplete information setting, exploring how different kinds of classifiers can induce hugely varying levels of desirable effort from strategic agents and quantifying the achievable limits of desirable behavior as a function of uncertainty. These experiments provide key insights on how a principal can incentivize desirable effort from agents, even under general settings of incomplete information. For more details, we refer the reader to our paper Efthymiou et al. (2025).
References
- Yahav Bechavod, Katrina Ligett, Steven Wu, and Juba Ziani. Gaming helps! learning from strategic interactions in natural dynamics. In International Conference on Artificial Intelligence and Statistics, pages 1234–1242. PMLR, 2021.
- Yahav Bechavod, Chara Podimata, Steven Wu, and Juba Ziani. Information discrepancy in strategic learning. In International Conference on Machine Learning, pages 1691–1715. PMLR, 2022.
- Lee Cohen, Saeed Sharifi-Malvajerdi, Kevin Stangl, Ali Vakilian, and Juba Ziani. Bayesian strategic classification. arXiv preprint arXiv:2402.08758, 2024.
- Raman Ebrahimi, Kristen Vaccaro, and Parinaz Naghizadeh. The double-edged sword of behavioral responses in strategic classification: Theory and user studies. arXiv preprint arXiv:2410.18066, 2024.
- Valia Efthymiou, Chara Podimata, Diptangshu Sen, and Juba Ziani. Incentivizing desirable effort profiles in strategic classification: The role of causality and uncertainty. arXiv preprint arXiv:2502.06749, 2025.
- Ganesh Ghalme, Vineet Nair, Itay Eilat, Inbal Talgam-Cohen, and Nir Rosenfeld. Strategic classification in the dark. In International Conference on Machine Learning, pages 3672– PMLR, 2021.
- Moritz Hardt, Nimrod Megiddo, Christos Papadimitriou, and Mary Wootters. Strategic classification. In Proceedings of the 2016 ACM conference on innovations in theoretical computer science, pages 111–122, 2016.
- Wan Shakira Rodzlan Hasani, Kamarul Imran Musa, Xin Wee Chen, and Kueh Yee Cheng. Constructing causal pathways for premature cardiovascular disease mortality using directed acyclic graphs with integrating evidence synthesis and expert knowledge. Scientific Reports, 14(1):28849, 2024.
- Jon Kleinberg and Manish Raghavan. How do classifiers induce agents to invest effort strategically? ACM Transactions on Economics and Computation (TEAC), 8(4):1–23, 2020.
- John Miller, Smitha Milli, and Moritz Hardt. Strategic classification is causal modeling in disguise. In International Conference on Machine Learning, pages 6917–6926. PMLR, 2020.
- Yonadav Shavit, Benjamin Edelman, and Brian Axelrod. Causal strategic linear regression. In International Conference on Machine Learning, pages 8676–8686. PMLR, 2020.
About The Author
Diptangshu Sen
PhD student at Georgia Tech ISyE